RAG
简介
检索增强⽣成(RAG)是指对⼤型语⾔模型输出进⾏优化,在 LLM 本就强⼤的功能基础上,RAG 将其 扩展为能访问特定领域或组织的内部知识库,所有这些都⽆需重新训练模型。这是⼀种经济⾼效地 改进 LLM 输出的⽅法,让它在各种情境下都能保持相关性、准确性和实⽤性。
优点
- 经济⾼效:RAG 是⼀种将 新数据引⼊ LLM 的更加经济⾼效的⽅法。它使⽣成式⼈⼯智能技术更⼴泛地获得和使⽤。
- 实时信息:RAG 允许开发⼈员 为⽣成模型提供最新的研究、统计数据或新闻
- 更多的控制权:可以控制和更改 LLM 的信息来源,以适应不断变化的需求或跨职能使⽤。开发⼈员还可以将敏感信息的检索限制在不同 的授权级别内,并确保 LLM ⽣成适当的响应。
工作流
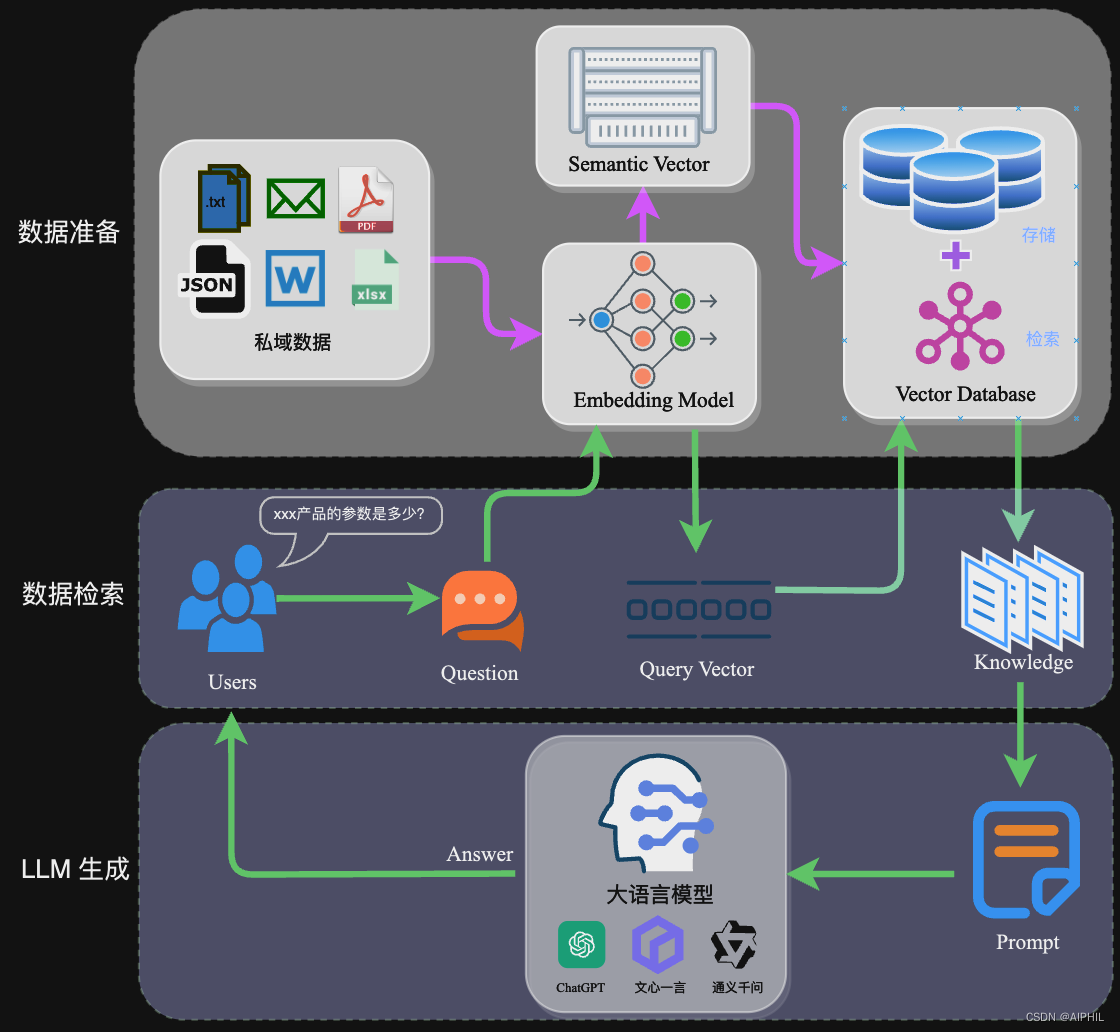
1、准备阶段
- 准备私域数据
- 文档解析:使用不同的文档解析器对文件内容进行解析,并获取到具体的文件内容
- 文档分块(chunk):采用合适的分块技术,对文档内容进行合适的切割,分出多个文档块
- 文档块 Embedding:将切割好的文档块通过Embedding Model转换给Semantic Vector
- 存储向量到向量数据库中
2、应用阶段
- 用户输入 Query
- 将 Query 通过 Embedding 转换成向量
- 将相似文档块召回
- 注入到 prompt 中
- 通过 LLM 生成最终回答
Document loaders
文件加载可以使用 langchain_community.document_loaders 中的加载器,非常完善,可以加载各种格式的文件
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders import CSVLoader
from langchain_community.document_loaders import UnstructuredExcelLoader
from langchain_community.document_loaders import UnstructuredHTMLLoader
from langchain_community.document_loaders import BSHTMLLoader
from langchain_community.document_loaders import JSONLoader
from langchain_community.document_loaders import PyPDFLoader
# 加载markdown文本
mdLoader = TextLoader("assets/test.md")
mdDocument = mdLoader.load()
# 加载 cvs 文件
csvLoader = CSVLoader(file_path="assets/test.csv")
csvDocument = csvLoader.load()
# 加载 excel 文件
excelLoader = UnstructuredExcelLoader("assets/test.xlsx")
excelDocument = excelLoader.load()
# 加载 html 文件
htmlLoader = UnstructuredHTMLLoader("assets/test.html")
htmlDocument = htmlLoader.load()
# 加载 html 文件,并且只获取文本内容,去除标签
bshtmlLoader = BSHTMLLoader("assets/test.html")
bshtmlDocument = bshtmlLoader.load()
# 加载 json 文件
jsonLoader = JSONLoader(file_path="config/simplePrompt.json", jq_schema=".template")
jsonDocument = jsonLoader.load()
# 加载 pdf 文件
pdfLoader = PyPDFLoader("assets/test.pdf")
pdfDocument = pdfLoader.load_and_split()
Text Splitters
RecursiveCharacterTextSplitter(递归切割)
根据一组分隔符递归地分割文本。默认分隔符列表为 ["\n\n", "\n", " ", ""],它会依次尝试这些分隔符,优先保持段落、句子和单词的完整性。
以下是其关键参数:
- chunk_size: 每个分割片段的最大字符数。
- chunk_overlap: 相邻片段之间的重叠字符数,用于减少上下文丢失。
- length_function: 用于计算片段长度的函数,默认是
len。 - is_separator_regex: 指定分隔符是否为正则表达式。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
" ",
".",
",",
"\u200b", # 零宽空格
"\uff0c", # 全角逗号
"\u3001", # 表意逗号
"\uff0e", # 全角句号
"\u3002", # 表意句号
"",
],
chunk_size=100,
chunk_overlap=20
)
docs = text_splitter.split_documents(documents)
还可以切割编程语音,它会优先保障代码的完整性
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters import Language
'''
编程语言切割
像copilot底层原理,根据编程语言来切割文本
'''
PYTHON_CODE = """
def hello():
print("hello")
# 调用函数
hello() # 1111
def cc():
print("cc")
"""
py_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON,
chunk_size=50,
chunk_overlap=10,
)
python_docs = py_splitter.create_documents([PYTHON_CODE])
print(python_docs)
[
Document(metadata={}, page_content='def hello():\n print("hello")\n# 调用函数'),
Document(metadata={}, page_content='# 调用函数\nhello() # 1111'),
Document(metadata={}, page_content='def cc():\n print("cc")')
]
SemanticChunker
通过 LLM Embedding 库,对文章进行语义理解,将相似语义切割为一个chunk
from langchain_experimental.text_splitter import SemanticChunker
from langchain_openai import OpenAIEmbeddings
text_splitter = SemanticChunker(OpenAIEmbeddings())
docs = text_splitter.create_documents([knowledge])
此拆分器的工作原理是确定何时“断开”句子。这是通过查找任意两个句子之间的嵌入差异来完成的。当该差异超过某个阈值时,它们就会被拆分
有几种方法可以确定该阈值,这由 breakpoint_threshold_type 关键字参数控制
- 百分位数(默认):任何语义大于
breakpoint_threshold_amount设定的chunk会被拆分
SemanticChunker(
OpenAIEmbeddings(),
breakpoint_threshold_type="percentile",
breakpoint_threshold_amount=50
)
- 梯度:距离的梯度与百分位数方法一起用于分割文本块。当文本块彼此高度相关或特定于某个领域(例如法律或医学)时,此方法非常有用。其思想是对梯度数组应用异常检测,以便使分布更广,更容易在高度语义化的数据中识别边界。与百分位数方法类似,分割可以通过关键字参数
breakpoint_threshold_amount进行调整,该参数期望一个介于0.0和100.0之间的数字,默认值为95.0。
SemanticChunker(
get_text_embedding_3_small(),
breakpoint_threshold_type="gradient",
breakpoint_threshold_amount=50
)
langchain agent 实现
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_core.tools.retriever import create_retriever_tool
from langchain_core.prompts import PromptTemplate
from langchain.agents import create_react_agent, AgentExecutor
from langchain.memory import ConversationBufferMemory
from my_openai.text_embedding_3_small import get_text_embedding_3_small
from my_openai.deepseekv3 import get_deepseek_v3_client
class RAG:
def __init__(self, path: str):
self.path = path
self.memory = ConversationBufferMemory(memory_key="chat_history")
self.agent_executor = self.get_agent()
def get_retiever(self):
# 加载文档
loader = TextLoader(self.path)
docs = loader.load()
# 切割文档
text_splitter = RecursiveCharacterTextSplitter(
separators=[
"\n\n",
"\n",
" ",
".",
",",
"\u200b", # 零宽空格
"\uff0c", # 全角逗号
"\u3001", # 表意逗号
"\uff0e", # 全角句号
"\u3002", # 表意句号
"",
],
chunk_size=100,
chunk_overlap=20
)
splits = text_splitter.split_documents(docs)
# 定义向量数据库
db = Chroma.from_documents(splits, get_text_embedding_3_small())
# 返回langchain标准retriever
retriever = db.as_retriever()
return retriever
def get_tools(self):
retriever = self.get_retiever()
tool = create_retriever_tool(
retriever,
"文档检索",
"用于检索用户提出的问题,并基于检索到的文档内容进行回复"
)
return [tool]
def get_agent(self):
instructions = """
您是一个设计用于查询文档来回答问题的代理。
您可以使用文档检索工具,并基于检索内容来回答问题
您可能不查询文档就知道答案,但是您仍然应该查询文档来获得答案。
如果您从文档中找不到任何信息用于回答问题,则只需返回“抱歉,这个问题我还不知道。”作为答案。
"""
base_prompt_template = """
{instructions}
TOOLS:
------
You have access to the following tools:
{tools}
To use a tool, please use the following format:
•```
Thought: Do I need to use a tool? Yes
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
•```
When you have a response to say to the Human, or if you do not need to us
e a tool, you MUST use the format:
•```
Thought: Do I need to use a tool? No
Final Answer: [your response here]
•```
Begin!
Previous conversation history:
{chat_history}
New input: {input}
{agent_scratchpad}"""
base_prompt = PromptTemplate.from_template(base_prompt_template)
prompt = base_prompt.partial(instructions=instructions)
# 创建llm
llm = get_deepseek_v3_client()
# 构建agent
agent = create_react_agent(llm, tools=self.get_tools(), prompt=prompt)
# 构建agent递归执行器
agent_executor = AgentExecutor(agent=agent, tools=self.get_tools(), memory=self.memory, verbose=True)
return agent_executor
def query(self, query: str):
return self.agent_executor.invoke({"input": query})
rag = RAG("assets/test.txt")
print(rag.query("执剑人是什么?"))