分词规则
查看分词结果
GET /表名/_analyze
{
"field": "字段名",
"text": "Eating an apple a day & keeps the doctor away"
}
默认分词
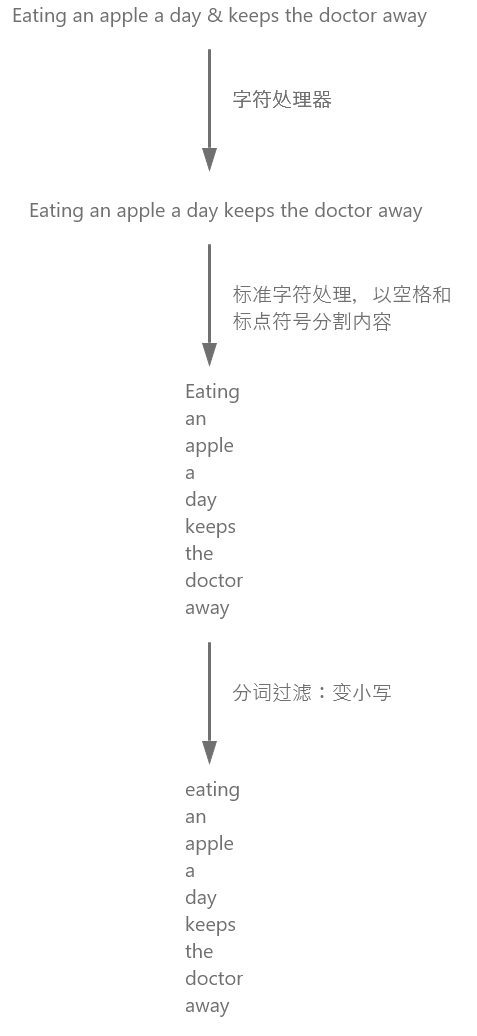
英语分词
PUT /movie
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
}
}
}
}
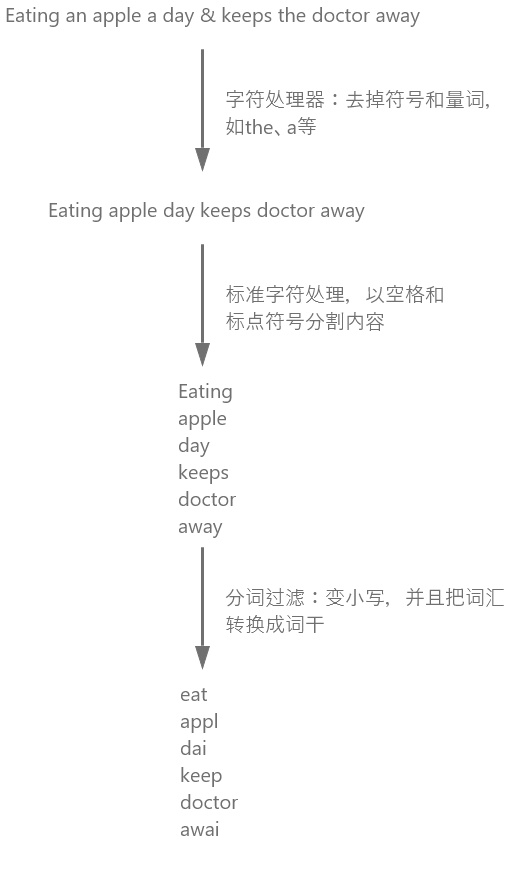
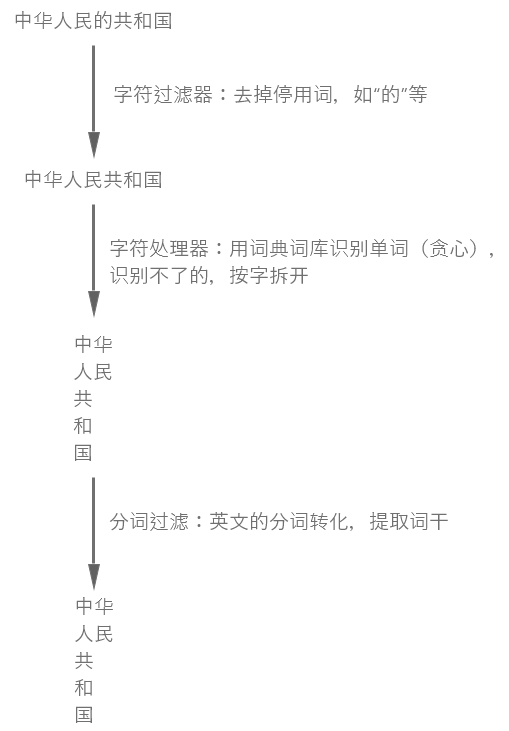
中文分词
安装中文分词器(Ik插件)
命令行安装
cd bin elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.11.1/elasticsearch-analysis-ik-7.11.1.zip在 官网 中的 release 中下载对应版本的压缩包
到 elasticSearch 的 plugins 下解压
2种分词规则
- ik_smart:尽最精简的分出词语。一般用于搜索关键词的分词
- ik_max_word:只要匹配词库的,就选出。一般用于索引分词
例子:中华人民共和国国歌
ik_smart:中华人民共和国、国歌
ik_max_word:中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、共和、国、国歌
词库扩展
在
ik/config创建新的词库文件xx.dic在
xx.dic加入词,每个词一行你好 你不好把
xx.dic用 utf-8 编码在
IKAnalyzer.cfg.xml中加入词库文件<!--用户可以在这里配置自己的扩展字典 --> <!--多个文件以;分隔 --> <entry key="ext_dict">xxx1.dic;xxx2.dic</entry>